Where were you on 30 November, 2022? When OpenAI made ChatGPT vers. 3.5 generally available? By some accounts, the heavens opened up, showering us with new knowledge and tools for creating valuable content. Five months on, consumer-facing, generative AI has started a frenzy, and is often confused with “artificial intelligence” ~ although it’s but one animal in the AI ‘taxonomy’. Beyond that, predictive analytics and other complex decision support tools are often grouped with machine learning and AI algorithms.
AI for decisioning
We can get only so far talking about decision-making without diving into a specific knowledge domain – evaluating AI for specific, evidence-based medical decisions, for instance, would require its own series of posts. But foundational concepts apply to activities such as advocating particular decisions or providing background information: Citing reliable sources is a must.
Museum of AI has been following how the new generative AI tools are (or are not) citing/linking to sources they rely on when providing answers. The products are changing so rapidly that we’re rather busy keeping up: Read Part 1 and Part 2 of this series.
Are chatbots trustworthy?
The main thing to remember is that it’s nearly impossible to affirmatively show how a particular bot arrived at a particular response: GPTs (generative pretrained transformers) can cite sources only in certain circumstances. In fact, consumer-facing tools based on LLMs (large language models) are so new, and trained on so much data, that they often generate different text sequences (a/k/a answers) when asked the same question more than once. Human testing is nowhere near over.
It gets worse. “ChatGPT doesn’t just get things wrong at times, it can fabricate information (subtle difference?). Names and dates. Medical explanations. The plots of books. Internet addresses. Even historical events that never happened.” This from the New York Times piece When A.I. Chatbots Hallucinate (1 May 2023).
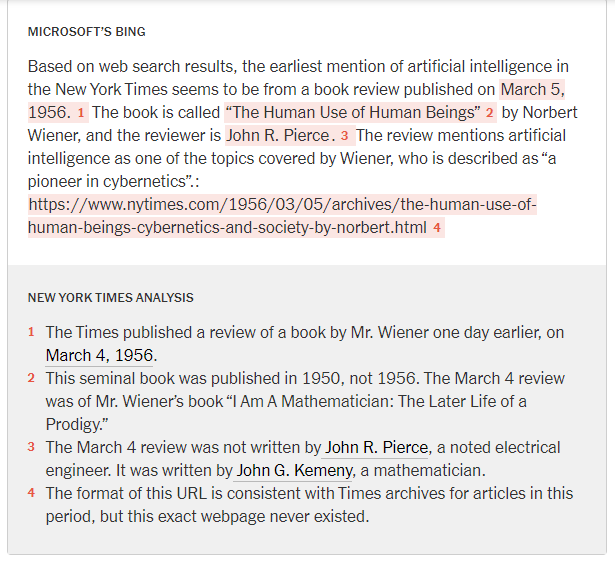
The New York Times asked the bots when the paper first mentioned ‘artificial intelligence’. Kudos to NYT for formatting their conclusions like footnotes (there’s a similar chart for Bard). Let it be said that these responses aren’t giant clusters of random ‘facts’ ~ they’re in the ballpark for sure.
Let’s be clear, sometimes they do make s%!t up, a behavior unfortunately named hallucination, where the AI gives a confident response unsupported by training data. “‘If you don’t know an answer to a question already, I would not give the question to one of these systems,’ said Subbarao Kambhampati, a professor and researcher of artificial intelligence at Arizona State University.” Okay, I’ll bite: Why would you ask a question if you already knew the answer? Perhaps you’re looking to doublecheck your recall? Don’t go to a Chatbot for that.
So you need evidence to support a decision…
Some observers suspect humans of doing the hallucinating, as tech hype rises to very high levels, and copyright issues are raised. Museum of AI doesn’t recommend relying on the platforms’ output for projects where solid evidence is a must. Better to pretend it’s still 29 November, 2022 and source your evidence pre-ChatGPT-style: Your options are incredible (and maybe even verifiable).
A chatbot might point you in a direction you had not considered, identify a new alternative, and provide different perspective. Or it might provide answers you believe are trustworthy because you know the subject. But evidence shows they don’t fully have a solid handle on historical facts.






